

Muzz social is the largest muslim social network in the world, we allow for users to post, comment and share their experiences with each other.
Background
At the start of the year we added a simple but effective impressions system. We used the page which the user was requesting to be counted as an impression, we then stored the results of this inside ElastiCache (Valkey). Every time the feed was requested we would then exclude the posts unless the comment count had changed by a significant amount. This change created a very positive change for our users seeing a 22% increase in feed requests over the two months after we rolled out the feature. However there was an inherent issue with this which was that just because the whole page was requested it does not mean it had been seen. So quickly after this was released we started work on its successor named mobile impressions. The system was to be near real time, it also had to be durable as we did not want to drop events as this could cause inconvenience to the users. This was no mean feat as we handle around 150,000 events a minute all of this would need to be processed and handled as quickly as possible. Muzz social uses an event driven architecture meaning when certain actions happen it creates events which can be tapped into this allows us to extend existing functionality in a scalable and controllable way.
Goals
One of our main priorities with this project was durability and throughput. At muzz we make use of queues(SQS) extensively as it allows us to have a retry mechanism if requests fail due to a networking issue or a service was not able to respond. Additionally due to our checkpointing system for our Kinesis reader, if a part of the shard failed, the whole shard would be re-tried, which allows for the durability of events into the system.
Another important goal was interoperability with the mobile client versions, because mobile devices are updated in a rolling release we chose not to do a big bang style product delivery additionally it would be harder for us to estimate load and throughput. Instead we used a feature header on the app to signal to the backend to use the new impressions system when requesting the feed. This allowed us to keep versions of impression systems working together. Additionally it allows us to have a kill switch for the feature.
Implementation
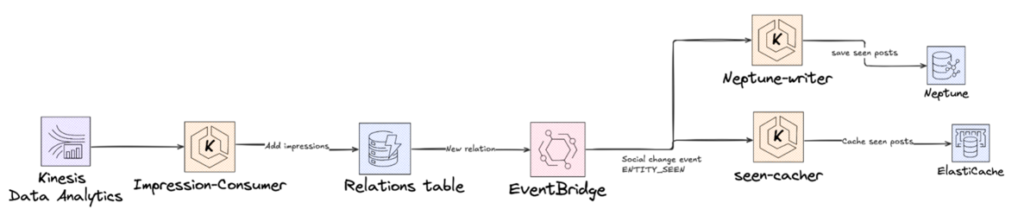
In order to do this we created a new Kinesis consumer which read our mobile logs looking for seen impressions, this would trigger and add a record into the relations table(a table used to store group membership as well as likes, comments and replies) via a gRPC call to our relations service.
Our relations table has a lambda which listens to changes on our relations table that is then able to add events onto an Event bridge with the social profile seeing the event and the post seen as well as an Enum of the type of event thus creating our SeenPost events.
type Entity_PostSeen struct {
SocialProfileId string `json=socialProfileId" json:"social_profile_id`
PostId string `json=postId,proto3" json:"post_id,omitempty"`
SeenAt int64 `json=seenAt,proto3" json:"seen_at,omitempty"`
}
After the event is created two downstream services consume it. The first is our existing Neo4j writer which adds relations to our graph database which we use to generate feed. The second is our cache writer that adds posts seen to the cache which is used to avoid posts which have already been seen. An issue we highlighted at the start of the project was that not all of the data we were storing was important to store after it had been processed. For this reason we made use of DynamoDB Time to live (TTL) to automatically delete records which were older than a set amount. Additionally this allows for a deletion event to be created thus being removed from downstream services.
Evaluation
In order to evaluate if the system was working optimally I created a dashboard which allows us to track the events across the key components of the impressions system, for example if the cache and the graph are misaligned this could point to a wider problem.
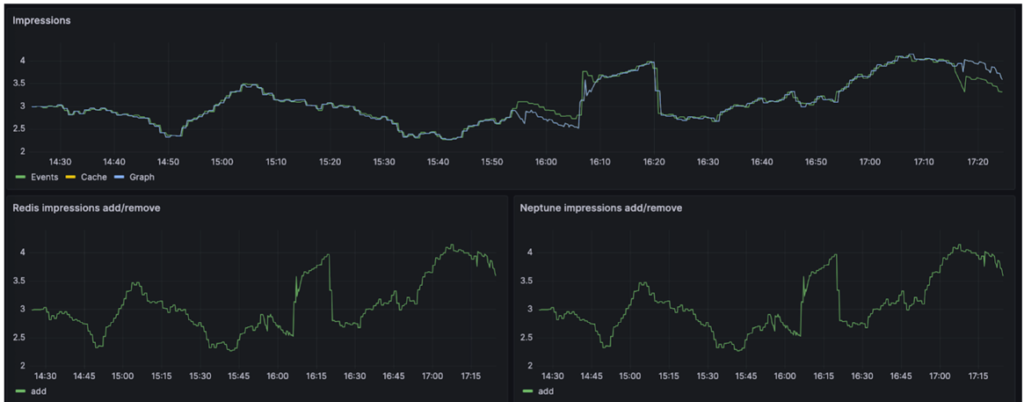
Indeed thanks to this metric we were able to easily observe the service being degraded due to insufficient resources and underutilisation of concurrency. Additional complexity came due to concurrent writes. If you imagine we process 10 events 5 might be from the same user and we spawn goroutines(A goroutine is a lightweight thread of execution) for each of them each of these create events which are consumed downstream, this might be the case with writes conflicting with each other. For that reason we had to implement a distributed locking system using redis to fix this issue. In this solution a cache stores if a key exists for the user if not it acquires the locks else it waits until it can get the lock, this way the goroutines are not conflicting with each other. The overall system handles around 1.6 million events per day with only two messages dropped in two months of operation.


